Modern healthcare systems generate a tremendous volume of data at a pace that can easily overwhelm traditional statistical analytics models. This immense number of individual datapoints can make it challenging to identify complex interactions and relationships that may have a clinical significance [1,2].
Machine learning is a sub-field of artificial intelligence. It is a field that involves computer algorithms that are given the capability to learn from data. This results in model generation of complex rules from the data itself, rather than from relying on strict rubrics inputted manually. Relationships between inputted data [variables such as demographics, physiological data, laboratory values, etc.] and outcomes [mortality, presence of infection, acute kidney injury, etc.] can be uncovered even when not immediately obvious to a trained expert. In recent years, there has been a surge of literature using machine learning in healthcare research; some articles are highlighted in table 1 [3-7].
Table 1. Recent studies using a machine learning approach to analyze large amounts of data
Article |
Journal |
Population |
Methods |
Results |
Machine Learning for Real-time Prediction of Complications in Critical Care: A Retrospective Study |
Lancet Respiratory Medicine 2018
http://dx.doi.org/10.1016/ S2213-2600(18)30300-X |
47 559 ICU admissions
Adult patients who underwent open heart surgery |
Deep Learning (Recurrent Neural Network) to predict severe complications |
Accurate predictions of mortality, renal failure, and bleeding |
Applying Machine Learning to Pediatric Critical Care Data |
Pediatric Critical Care Medicine 2018
DOI:
10.1097/PCC.0000000000001567 |
11,384 PICU Episodes |
K Means clustering |
10 clusters (based on mortality, length of stay, use of ventilation, pressors and diagnosis), cluster membership predicted mortality |
Applying Artificial Intelligence to Identify Physiomarkers Predicting Severe Sepsis in the PICU |
Pediatric Critical Care Medicine 2018
DOI: 10.1097/PCC.0000000000001666 |
493 ICU patients |
Logistical regression, random forests, and deep Convolutional Neural Networks |
83% specificity and 75% sensitivity in predicting sepsis |
The Artificial Intelligence Clinician Learns Optimal Treatment Strategies for Sepsis in Intensive Care |
Nature Medicine 2018
https://doi.org/10.1038/s41591-018-0213-5 |
2 Large databases (17083 and 79073 patients) |
Reinforcement Learning for AI clinician, and Markov Decision process to model patient environment and trajectories |
AI clinician selected treatment is on average reliably higher than human clinicians |
Dynamic Mortality Risk Predictions in Pediatric Critical Care Using Recurrent Neural Networks |
ARXIV |
12000 Patients |
Recurrent Neural Network |
RNN generated temporally dynamic predictions for ICU mortality – AUROC >93% better than PIM2 or PRISM 3. |
Types of machine learning
There are several forms of machine learning, distinguished by the mechanisms the algorithm uses to handle data. One way to classify types of machine learning is to sort the approach as supervised vs. unsupervised.
Supervised machine learning
Supervised machine learning consists of using labelled data to train an algorithm [8]. This involves starting with a set of data that includes “input-output” pairs. These are then used as an example, through which the system deduces the relationship between the input and output and creates an algorithm. This algorithm is then tested on data that was not included in the training example, in order to clarify whether the initial inferred relationship was true. In general, supervised machine learning methods are best used in applications where historical data can predict upcoming events. Supervised machine learning can be further split into a regression or classification approach [9].
Regression is used with continuous data, in situations where the relationship between the dependent and independent variables is continuous. Examples include liner regression, polynomial regression, vector regression, Random Forest regression, and Bayesian regression.
Classification is used to make predictions when the relationship between the variables is non-continuous. Examples include K-nearest neighbors, Naive Bayes, Random Forest classification, and decision tree classification.
Unsupervised machine learning
Unsupervised machine learning consists of self-organized learning that can find previously unknown or unseen patterns within a data set, without pre-existing human labels or labeled measurements [10,11]. The purpose of unsupervised learning is to explore data and find relationships within the data. The main types of unsupervised learning are clustering and dimensionality reduction.
Clustering algorithms include K-Means clustering and hierarchical clustering. In an unsupervised clustering algorithm, similar datapoints are grouped together in clusters. New datapoints are inspected and assigned to the “cluster” they belong. As defined “clusters” emerge, each will have its own center which serves as the “mean” or “center” for the cluster. This “mean” is continuously recalculated as new datapoints are added, and cluster membership is continuously refined as the mean is redefined.
Dimensionality reduction is a form of unsupervised learning in which the algorithm seeks to “clean” the data, relying on patterns within the data to remove undesirable or non-contributory information. This helps with improving the predictive performance of algorithms, and the data can then be analyzed more efficiently with other forms of machine learning.
Neural Networks and Deep Learning
Artificial neural networks are computing systems inspired by biological neural networks [12]. Depending on the type of neural network, a supervised or unsupervised approach can be used. Neural networks are formed by artificial neurons, organized in layers as in the figures 1-3 below. The layers are an input layer, an output layer, and “hidden” layers in between. Neural networks attempt to look at varying inputs [labs, physiological variables, etc.] and apply a function [a series of calculations] to create a new (hidden) layer. Hidden layers are commonly referred to as such since it is not clear to an observer what layers are being created or what calculations are being performed in these layers.
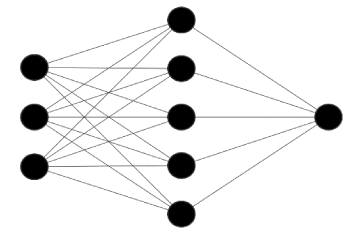
Figure 1. Simple neural network with single hidden layer
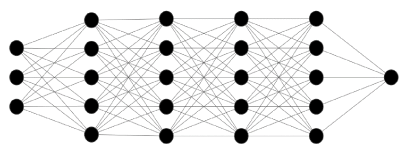
Figure 2. Neural network with several hidden layers. Number of connections, or "synapses", increase exponentially with each added layer. This serves to increase the networks data -processing ability
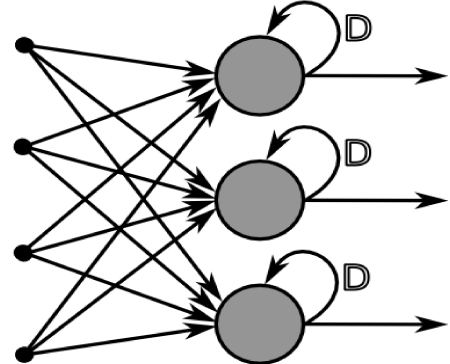
Figure 3. A layer from a recurrent neural network. The network is able to learn from its results and can alter a hidden layer to improve its performance
Neural networks are classified based on the number of hidden layers, and how these layers connect. Networks that utilize multiple layers are commonly referred to as “deep learning” networks [13]. With more layers, more connections [also known as synapses] form between the individual layers, leading to a capacity to handle exponentially larger amounts of data. In fact, the biggest strength of deep learning networks is the capability of handling non-linear, complex datasets with billions of parameters.
Recurrent neural networks (RNN) are a specialized form of neural networks being increasingly used in research (Figure 3). In addition to the ability to process large amounts of data, an RNN has the ability to “learn”. If the network incorrectly predicts an output, it may use that information to go back and alter a function or specific layers to alter predicted outcomes on future samples, correcting “its mistake” and improving future function.
As machine learning becomes more common in biological science clinical research, it is critical to understand its limitations [14,15]. The data is processed in hidden layers, so understanding that there may be a lack of insight into how an algorithm arrives at its conclusion should factor into the interpretation of the findings [16]. Results are frequently reported in confusion matrices, which are composed of true positives, true negatives, false positives and false negatives. Accuracy only represents the total correct classifications (TP+TN) divided by total cases and is a fairly crude measure of a model. It is important to note that this accuracy does not represent sensitivity, specificity, positive and negative predictive values, which may be more clinically relevant.
Because some forms of machine learning can process large data sets with seemingly little oversight, it is important to ensure the correctness of inputted data in order to avoid generating models based on improper data. It is also important to be cognizant of the amount of data available in a dataset – small datasets may not be best served with a machine learning approach.
Machine learning approaches generate information that is often unreported in academic clinical research. This includes:
- Loss: how well the model is performing over serial versions/epochs
- Accuracy: a model can become highly accurate but not generalizable to external data
- F1 scores: a measure of recall and precision
Unfortunately, there is a lack of a standardized approach with regards to reporting of results uncovered using a machine learning approach. Like how researchers report specific statistical tools/methods used, we advocate that machine learning literature report the details of the actual model, as well as measures of strength of the model, to ensure that findings are both accurate and reproducible.
Machine learning holds great promise for analyzing large data sets and identifying previously unknown but clinically relevant patterns and associations. As machine learning becomes a tool in the research arsenal, researchers must ask a series of important questions including: How complex is the task and how many variables are involved? How many examples exist to train and validate the model? How interpretable and generalizable does the model need to be? Can this task be accomplished using a traditional statistical approach? If so, what will a machine learning approach add?
Researchers must also be familiar with the methods used and with the limitations of such an approach. Understanding such issues allows for appropriate translation from research to the clinical realm in an appropriate manner.
- Jensen PB, Jensen LJ, Brunak S (2012) Mining electronic health records: towards better research applications and clinical care. Nat Rev Genet 13: 395-405.
- Luo J, Wu M, Gopukumar D, Zhao Y (2016) Big data application in biomedical research and health care: a literature review. Biomed Informn Insights 8: BII.S31559.
- Aczon M (2017) Dynamic Mortality risk predictions in pediatric critical care using recurrent neural networks. ArXiv170106675 Cs Math Q-Bio Stat.
- Kamaleswaran R (2018) Applying artificial intelligence to identify physiomarkers predicting severe sepsis in the picu. Intensive Crit Care Soc 19: e495-e503.
- Komorowski M, Celi LA, Badawi O, Gordon AC, Faisal AA T, et al. (2018) The Artificial Intelligence Clinician learns optimal treatment strategies for sepsis in intensive care. Nat Med 24: 1716-1720.
- Meyer A (2018) Machine learning for real-time prediction of complications in critical care: a retrospective study. Lancet Respir Med 6: 905-914.
- Williams J, Ghosh D,Wetzel RC (2018) Applying Machine Learning to Pediatric Critical Care Data. Pediatr. Crit Care Med 19: 599.
- Fabris F, Magalhaes JP, Freitas AA (2017) A review of supervised machine learning applied to ageing research. Biogerontology 18: 171-188.
- Caruana R, Niculescu-Mizil A (2006) An Empirical Comparison of Supervised Learning Algorithms. in Proceedings of the 23rd International Conference on Machine Learning 161-168 (ACM, 2006).
- Barlow HB (1989) Unsupervised Learning. Neural Comput 1: 295-311.
- Radford A, Metz L, Chintala S (2015) Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. ArXiv151106434 Cs.
- Basheer IA, Hajmeer M (2000) Artificial neural networks: fundamentals, computing, design, and application. J Microbiol Methods 43: 3-31.
- Miikkulainen R (2019) Chapter 15 - Evolving Deep Neural Networks. in Artificial Intelligence in the Age of Neural Networks and Brain Computing (eds. Kozma, R., Alippi, C., Choe, Y. & Morabito, F. C.) 293-312 (Academic Press, 2019).
- Shameer K, Johnson KW, Glicksberg BS (2018) Machine learning in cardiovascular medicine: are we there yet? Heart 104: 1156-1164.
- Jarrett D, Stride E, Vallis K, Gooding MJ (2019) Applications and limitations of machine learning in radiation oncology. Br J Radiol 92: 20190001.
- Ananny M, Crawford K (2018) Seeing without knowing: Limitations of the transparency ideal and its application to algorithmic accountability. New Media Soc 20: 973-989.