Trichloroethylene (TCE) induced occupational medicamentosa-like dermatitis (OMDT) is a systemic skin disorder accompanied by liver dysfunction in workers occupationally exposed to TCE. The present study employed massive parallel sequencing by AluScan developed by us to determine genetic variations associated with sensitivity to TCE exposure. With coverage of 14.54 Mb genome regions with at least four-fold depth across two OMDT patients and two control subjects, single-nucleotide polymorphism (SNP) rs941960 located in the CCBL1 gene coding for cysteine conjugate-beta lyase, and copy number gains in CYP2C9 and CYP3A4 were identified as plausible causal factors of OMDT, all of which are components of TCE metabolic pathways. These results ascertained that variants of these genes could increase the concentrations of metabolic intermediates of TCE that may act as antigens to trigger abnormal immunological responses and give rise to liver dysfunction.
AluScan, environmental toxicology, genetic toxicology, next-generation sequencing
1,1,2-Trichloroethylene is a colorless transparent liquid with odor like chloroform. It is widely used as a degreaser for metal parts for more than 70 years on account of its being an effective solvent for a variety of organic materials [1]. However, concern with the toxicity of TCE is increasing while the wide range of applications. Acute exposure to high concentrations TCE could cause headache, defatting dermatitis, lethargy, pulmonary edema, renal and hepatic damage, etc. In long-term exposure, patients experienced similar symptoms as in the acute exposure but with greater severity and persistence [2]. Risks of kidney carcinogenesis, liver carcinogenesis and non-Hodgkin lymphoma (NHL) were also enhanced with the long-term exposure [3]. In addition, a systemic skin disorder accompanied by liver dysfunction was reported in TCE occupational exposure cases. Differ from acute exposure cases, the severity of the disorder was not related to the concentrations or the duration of exposure; the period between onset and exposure was about one month, the mean age of patients was 29, and there was no bias between genders. Only a few cases were typically reported for any one work place [4]. The disorder has been reported in USA, England, Singapore, Japan, etc. In China, the number of cases increased significantly since the mid-1990. By 1998, there were at least 300 cases and several deaths reported, making this systemic skin disorder as one of the serious occupational health diseases [5]. In the diagnostic criteria of occupational medicamentosa-like dermatitis due to trichloroethylene (OMDT), this disorder is classified into four types: exfoliative dermatitis (ED), erythema multiform (EM), Stevens-Johnson syndrome (SJS), and toxic epidermal necrolysis (TEN) [6]. In skin sensitization test on guinea pig, IgG levels were found to be upgraded significantly suggesting that humoral immunity was involved in OMDT [7]. Immune tests in rats also showed that TCE can activate T lymphocytes, and stimulate B lymphocytes to secrete antigen-specific IgG antibodies [8]. Besides, several lines of evidence demonstrated the involvement of human leucocyte antigen DM (HLA-DM) [9], tumor necrosis factor (TNF) and interleukin 4 (IL-4) [10] in the immunological and inflammatory responses in OMDT. These studies suggested that OMDT might represent a type IV allergy. However, type IV allergies usually do not cause such serious illness with large areas of evident necrosis with peeling skin, and liver, kidney and other organ failures, raising the possibility that some metabolic products could be involved in the pathogenesis of OMDT. Accordingly, AluScan with high throughput DNA sequencing was applied in the present study to search for metabolic genes that can participate in OMDT etiology.
Alu elements are a family of primate-specific short interspersed nucleotide elements (SINE) originated from 7SL RNA [11] that contains the three major subtypes of Alu J, Alu S and Alu Y. There are over 1 million copies of Alu-elements comprising 10% of the human genome [12]. They are enriched in gene-rich regions and enhance recombination rates in the regions [13]. Variations surrounding a human lineage-specific Alu Y located in the GABRB2 gene were found to be associated with schizophrenia and bipolar disorder [14-15]. This region also constitutes a focal point for positive evolutionary selection [16] and a recombination hotspot [17].
AluScan sequencing, which amplifies inter-Alu sequences using Alu consensus sequence-based PCR primers for next generation sequencing (NGS), combines the advantages of the wide distribution of Alu elements with that of NGS to permit an examination of the gene-rich inter-Alu regions of human genome for candidate genes of diseases. The method reduces not only sequencing costs and computation workload but also DNA sample requirement to the sub-microgram level. With the use of three Alu consensual primers, it captures ~14 Mb amplicons between 0.2-6.0 kb in length if no mismatch in primers was allowed. Allowing single mismatches, coverage is increased to ~106 Mb [18]. Application of AluScan to a single pair of control and glioma DNA generated over 10 Mb sequences covering more than 8,000 genes, resulting in the identification of 357 loss of heterozygosities, 341 somatic indels, 274 somatic SNPs, and 7 potential somatic SNP hotspots [18]. Moreover, CNV can be called efficiently from AluScan sequencing data with an AluScanCNV package. In the present study, SNP and CNV analysis based on AluScans have been employed to identify the genomic basis of patients’ sensitivity to the TCE.
Blood samples
All study participants gave their written consent in accordance with the Declaration of Helsinki. Four samples of peripheral white blood cells including two cases (Case 1 and 2) and two controls (Control 1 and 2) were supplied by Shenzhen Center for Disease Control (CDC) (refer to Table S1 for more information). The two controls were similar in age as the cases. Biochemical analyses of the two patients (Table S2) provided by CDC suggested the presence of liver damage: Case 1 was diagnosed as ED, and Case 2 was diagnosed as EM. All DNA samples were extracted from peripheral blood using the AllPrep kit (Qiagen).
Inter-Alu PCR and next-generation sequencing
Four samples including the two cases and two controls were subjected to AluScan analysis as described previously [18] using the four Alu-consensual primers AluY278T18, AluY66H21, R12A/267 and L12A/8 (Figure S1). Sequence reads between 200 bp to ~ 6 kb in length were retrieved to build library and sequenced on the Illumina platform with 100 bp paired-end reads at BGI, Shenzhen China.
Read mapping and variant analysis
Sequence reads from each sample were mapped to the hg19 reference human genome employing BWA (bwa-short algorithm version 0.6.1-r104) with default settings. The mapping results were transformed into sorted BAM format and indexed with SAMtools version 0.1.19, mark duplicated with Picard (version 1.115), recalibrated and locally realigned using the Genome Analysis Toolkit (GATK version 2.1-8). The UnifiedGenotyper module in GATK was used to call the initial SNPs with the parameter ‘-dcov 50’. SNPs were filtered if more than one samples yielded a depth less than four-fold and genotyping quality was less than 10 at the site, and only SNPs with different genotypes between the cases and controls were retained for analysis. Indels were called by pindel (version 0.2.5a8) with default parameters. The results were also filtered to ensure at least eight folds coverage and indel lengths of less than 10 bp. The SNPs and indels obtained were annotated separately by SeattleSeq Annotation 138.
Pathway enrichment analysis
Genes bearing SNPs or indels were submitted to WebGestalt [19] for pathway enrichment analysis to determine the distribution within the KEGG database. All the genes submitted were classified according to the Go annotation prior to enrichment analysis. A hypergeometric test with Benjamini-Hochberg multiple comparison adjustment correction [20] was employed to assess the significance of gene enrichment, using the whole genome as the reference set. The top ten pathways enriched were selected to find differences between the cases and controls.
Variants verification
Potential SNPs on all four samples were selected for verification with two-step PCR. Following purification, the amplicons were loaded onto ABI 3130 Genetic Analyzer (PE Applied Biosystems) using the BigDyeTM Terminator Cycle Sequence kits with AmpliTaq DNA Polymerase to yield the DNA sequences for genotype determination.
CNV analysis
AluScanCNV package [21] was applied to the sequences data to reveal large extended CNVs. For this purpose, the reference genome was divided into contiguous 5 kb windows for the read-depth calculation. Neighboring windows with the same read-depth ratio were joined together by means of the circular binary segmentation algorithm. Genes located in regions where copy numbers were different between cases and controls were identified.
An average of ∼14 M reads was obtained for each individual DNA sample (Table 1,). Owing to higher duplication, the efficacious mapped reads of the cases were fewer than the controls. However, the coverage was still > 20 Mb for the cases with a depth ≥ 4. The overlap regions across all four samples amount to ∼ 14.54 Mb with at least four-fold depth, containing 7.52 Mb genic regions. Figure 1 and Table S3 show the distributions of reads and genetic variations occurring in each sample.
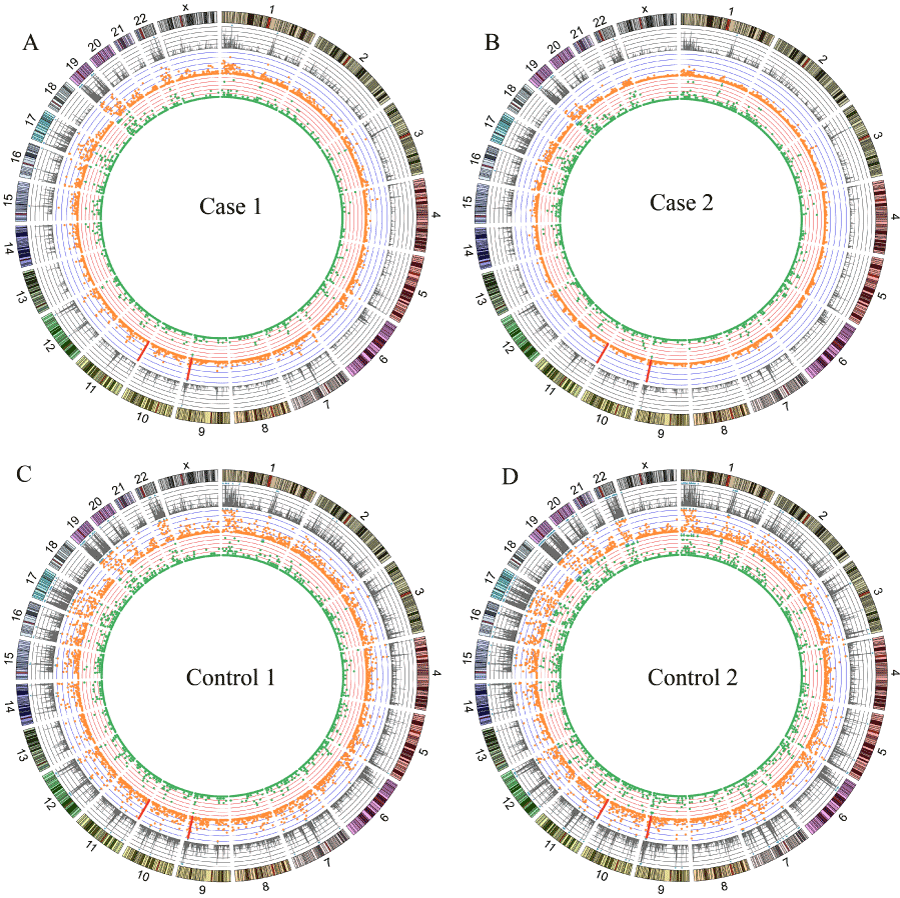
Figure 1. Read distribution and genetic variations identified in case 1 (A), case 2 (B), control 1 (C) and control 2 (D). From the outside, Tracks 1: the reads counts per 1Mb window (scale: 0-2M, 1 div =0.4M). Track 2: orange dots showing number of SNPs per 1 Mb window (scale: 0-60, 1 div =20). Track 3: green dots showing number of indels per 1 Mb window (scale: 0-10, 1 div =2). The blue triangle implied that the numbed of the window beyond the scale. The red bar pointed the position of SNPs rs941960 and rs11246020. Original data used to plot this figure can be found in Table S3.
A total of 6997 SNPs (Table S4) covering 1978 genes displayed different genotypes between the cases and controls. Among these SNPs, 2615 SNPs had been genotyped by dbSNP. Only 5 SNPs were missense and 3638 SNPs were located in introns (Figure 2). Furthermore, 398 indels (Table S5) covering 209 genes were called after filtration; 243 of the indels were located in introns, whereas no indel was located in coding regions (Figure 2). Merging all the genes with sequence variations, altogether 2070 genes were subjected to pathway enrichment analysis. Based on GO Slim classification (Figure S2), most of the genes belonged to the metabolic process. According to KEGG pathway enrichment analysis (Table 2), 124 of the genes containing mutated SNPs and indels were significantly enriched in metabolic pathways (Padj=1.57E-17), suggesting the possible involvement of genes in the metabolic process group.
Table 1. Statistics of AluScan mapping results of cases and controls.
|
Case 1
|
Case 2
|
Control 1
|
Control 2
|
Total initial reads (million pairs)
|
14.09
|
13.92
|
14.69
|
15.71
|
Duplicates(million reads)
|
7.86
|
7.06
|
2.62
|
4.20
|
Mapped(properly paired)
|
11.83
|
11.03
|
10.73
|
13.93
|
Genomic regions mapped with coverage ≥ 1 (Mb)
|
76.71
|
58.08
|
284.38
|
226.61
|
Mean Coverage
|
11.01
|
13.83
|
5.79
|
9.01
|
Genomic regions mapped with coverage ≥ 4 (Mb)
|
23.58
|
22.40
|
55.3
|
59.52
|
Gene regions mapped with coverage ≥ 4 (Mb)
|
12.14
|
11.51
|
28.91
|
31.3
|
Table 2. Top ten pathways of KEGG enrichment.
Pathway
|
C*
|
O†
|
R‡
|
Padj§
|
Metabolic pathways
|
1130
|
124
|
2.43
|
1.57E-17
|
Pathways in cancer
|
326
|
53
|
3.6
|
3.89E-14
|
Regulation of actin cytoskeleton
|
213
|
42
|
4.37
|
3.89E-14
|
Fc gamma R-mediated phagocytosis
|
94
|
26
|
6.12
|
2.30E-12
|
Focal adhesion
|
200
|
37
|
4.1
|
9.72E-12
|
ErbB signaling pathway
|
87
|
23
|
5.85
|
1.23E-10
|
Ubiquitin mediated proteolysis
|
135
|
28
|
4.59
|
3.10E-10
|
MAPK signaling pathway
|
268
|
40
|
3.3
|
7.98E-10
|
Chronic myeloid leukemia
|
73
|
20
|
6.07
|
1.00E-09
|
Insulin signaling pathway
|
138
|
27
|
4.33
|
2.06E-09
|
* C: the number of reference genes in the pathway
† O: the number of genes analyzed that belong to the pathway
‡ R: ratio of enrichment
§ Padj: P value adjusted by the Benjamini–Hochberg method [20]
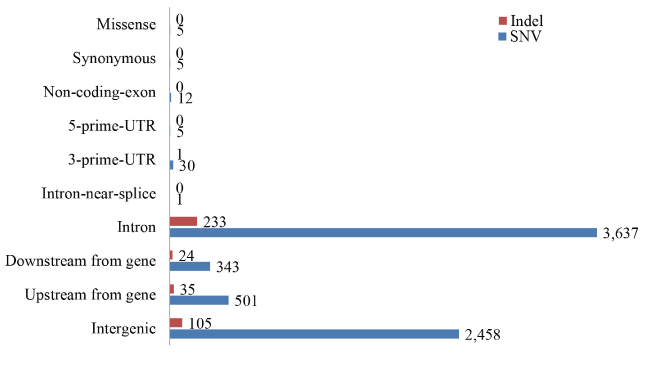
Figure 2. Distribution of SNPs and indels in the genomic sequences analyzed. Total 6997 SNPs and 398 indels were annotated, 52% variations were located in the intron region. Variations in upstream-gene or downstream-gene represent these variations are in 5 kb from a transcription region.
Based on the annotation results, two SNPs (rs941960 and rs11246020) were selected for verification by Sanger sequencing (Table 3). SNP rs941960 is located in the intron of cysteine conjugate-beta lyase (CCBL1) which was recorded in the database SNPedia as being highly correlated with renal carcinoma risk from TCE-exposure (OR 2.72) [22]. Another SNP rs11246020 is located in the coding region of SIRT3, the primary mitochondrial deacetylase that modulates metabolic and oxidative stress regulatory pathways in mitochondria [23], and participates in the acetylation of aldehyde dehydrogenase (ALDH) which was reported to be associated with TCE sensitivity [24]. However, the Sanger sequencing results showed SNP rs11246020 in control 1 was C/C in genotype, different from the AluScan C/T result, suggesting that this candidate SNP represented a false positive. Consequentially only SNP rs941960 displayed different genotypes between the cases and the controls, suggesting that CCBL1 with the G/C or C/C genotype in rs941960 was a causal factor of the patients’ sensitivity to TCE.
Table 3. SNPs rs941960 and rs11246020 in cases and controls.
| |
rs941960
|
rs11246020
|
Position of SNP
|
Chr9: 131641032
|
Chr11: 233067
|
Genotype in hg19
|
C
|
C
|
Gene name
|
CCBL1
|
SIRT3
|
Genotype in Case 1
|
G/C(G/C) *
|
C/C(C/C)
|
Genotype in Case 2
|
C/C(C/C)
|
C/C(C/C)
|
Genotype in Control 1
|
G/G(G/G)
|
C/C(C/T)
|
Genotype in Control 2
|
G/G(G/G)
|
C/T(C/T)
|
Nature of mutation
|
intron
|
Missense (VAL→ILE)
|
*Genotypes inside parentheses were the results from AluScan; genotypes outside parentheses were the results from Sanger sequencing.
In addition, with AluScanCNV analysis, 9 regions covering 4011 genes (Table 4) were found to be different in copy number between cases and controls. CYP3A4 (cytochrome P450, family 3, subfamily A, polypeptide 4, Chr7:99,354,604-99,381,888) and CYP2C9 (cytochrome P450, family 2, subfamily C, polypeptide 9, Chr10:96,698,415-96,749,147), both of which displayed increased expression in the TCE sensitive patients based on qPCR analysis [25], were found to be located in the copy number gain regions in the patients relative to controls. These two members of the cytochrome P450 family of oxidative enzymes therefore could also be significant factors underlying sensitivity to TCE.
Table 4. CNV regions in cases and controls.
Chr
|
Start
|
End
|
Case 1
|
Case 2
|
Control 1
|
Control 2
|
3
|
6,310,001
|
9,390,000
|
Loss
|
Loss
|
Neutral
|
Neutral
|
7
|
30,001
|
159,035,000
|
Gain
|
Gain
|
Neutral
|
Neutral
|
10
|
11,765,001
|
105,140,000
|
Gain
|
Gain
|
Loss
|
Loss
|
11
|
107,525,001
|
107,635,000
|
Neutral
|
Neutral
|
Gain
|
Gain
|
11
|
107,640,001
|
134,815,000
|
Neutral
|
Neutral
|
Gain
|
Gain
|
13
|
19,045,001
|
31,175,000
|
Neutral
|
Neutral
|
Loss
|
Loss
|
17
|
14,355,001
|
15,460,000
|
Loss
|
Loss
|
Gain
|
Gain
|
20
|
175,001
|
3,120,000
|
Loss
|
Loss
|
Neutral
|
Neutral
|
22
|
16,060,001
|
51,210,000
|
Neutral
|
Neutral
|
Gain
|
Gain
|
Genomic studies provide powerful 2021 Copyright OAT. All rights reservnship between occupational diseases and genetic variations. Based on the microarrays, a recent study revealed distinct transcriptional profile changes in gene regulation of the MAPK/ERK signaling cascade and ubiquitin–proteasome system between mice and rats, in accord with species-specific influences in liver carcinogenesis, upon exposure to TCE [26]. In this study, AluScan sequencing was employed to search for mutations in candidate genes that could play a role in OMDT pathogenesis through comparison of genomic sequences in OMDT patients and asymptomatic controls working in the same workplace. Although the number of available samples was limited, we found three genes that displayed genotypic differences between case and controls, all of which are known to participate in TCE metabolism.
There are two major pathways of TCE metabolism in the human body (Figure 3), viz. cytochrome P450 (CYP1/2)-dependent oxidation and conjugation with glutathione (GSH) catalyzed by glutathione S-transferases (GST) [27]. In the P450-dependent pathway, TCE is oxidized to chloral hydrate (CH) in the liver and lungs. CH undergoes oxidation by aldehyde dehydrogenase (ALDH) or reduction by alcohol dehydrogenase (ADH) to form trichloroacetate (TCA) or trichloroethanol (TCOH), respectively. A study on 108 OMDT patients and 145 healthy controls exposed to TCE in the same workplace found that the frequency of heterozygous ALDH2 in controls was significantly higher than in cases (43.4% vs 27.8%, P = 0.011), suggesting that ALDH2 produces the bioactive product TCA and its metabolite chloroacetic acid, which may form antigens upon combination with proteins [23]. Copy numbers of CYP3A4 and CYP2C9 could also affect individual susceptibility to OMDT. Results of human hepatic microsomal samples indicated that increase in CYP2E1 activity enhances individual susceptibility to TCE-induced toxicity [28]. Therefore, the copy number gains of CYP3A4 and CYP2C9 obtained in the present study could increase gene expression, thereby increasing transformation of TCE to chloral and TCA to result in the development of OMDT.
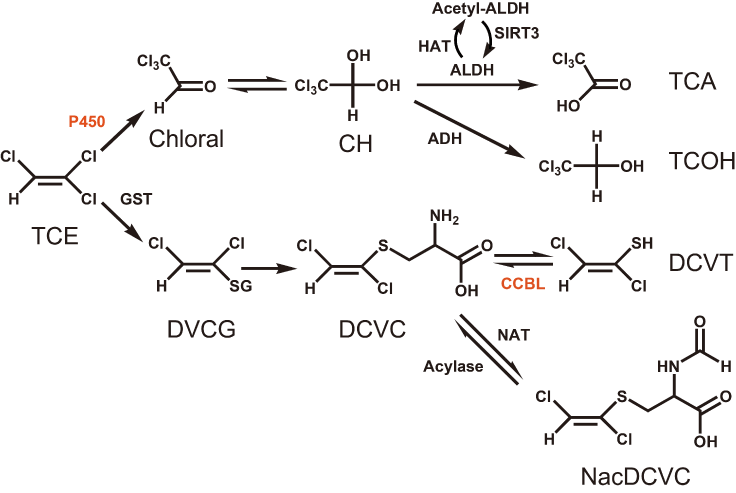
Figure 3. Metabolic scheme of TCE. A postulated scheme for the pathways of TCE metabolism is adapt from KEGG database and T. Shimazu et al. [20] . CYP3A4 and CYP2C9 are both member of P450 family which oxidize TCE to Chloral in the lung and liver. CCBL1 participate in the GSH pathway, transforming DCVC to DCVT.
In a second metabolic pathway, TCE is conjugated with GSH to form S-(1,2-dichlorovinyl) glutathione (DCVG) in the liver and kidneys. Next, DCVG is hydrolyzed by renal γ-glutamyltransferase to form S-(1,2-dichlorovinyl)-L-cysteine (DCVC). DCVC is bioactivated by cysteine conjugate β-lyase (CCBL) to form the reactive intermediate S-(1,2-dichlorovinyl) thiol (DVT), or detoxificated by N-acetyltransferase (NAT) to form N-acetyl-S-(1,2-dichlorovinyl)-Lcysteine (NAcDCVC). A previous study found that mutations in NAT2 could influence individual susceptibility to TCE-induced hypersensitivity dermatitis [27] due to reduction of NAT2 activity, thereby leading to the accumulation of the reactive intermediate DCVT, which may produce antigens that trigger an abnormal immunological response. Accordingly, the alteration in SNP rs941960 in CCBL1 found in the present study could affect this pathway by changing the activity of CCBL, and thereby the level of DCVT and induction of OMDT.
Since the genetic alterations, we found in CCBL1 and cytochrome P450 all participate in TCE metabolism, these results suggest that TCE metabolites are important to the development of OMDT. In keeping with these findings, pathway enrichment analysis also showed that the genomic differences between OMDT patients and controls were enriched in metabolic pathways. Therefore, the conclusion may be drawn that metabolites could lead to the production of active antigens to initiate the immune responses that are pivotal to the development of OMDT.
HX and SBL conceived and initiated the study and helped draft the manuscript; ZGW, PL, JFY, SYT participated in data analysis and wrote the paper. PL, MKM, YBK, XYX, GHL, JHY, GHL developed the clinical approach and provided samples. All authors have read and approved the final manuscript.
This work was partially supported by a collaborative research grant to HX by Key Laboratory of Genetics & Molecular Medicine of Shenzhen, Shenzhen Center for Disease Control and Prevention, Shenzhen, Guangdong, China. We are grateful to Professor J. Tze-Fei Wong for critical review of the manuscript. This study was supported by grants from Shenzhen scientific program (No.20110115) and Guangdong Provincial Science and Technology Project (2013B021800032).
View supplementary data
- Anagnostopoulos G, Sakorafas G, Grigoriadis K, Margantinis G, Kostopoulos P, et al. (2003) Hepatitis caused by occupational chronic exposure to trichloroethylene. Acta Gastro-Enterologica Belgica 67: 355-357.
- Fan AM (1988) Trichloroethylene: water contamination and health risk assessment. Reviews of Environmental Contamination and Toxicology: Springer. pp. 55-92.
- Guha N, Loomis D, Grosse Y, Lauby-Secretan B, El Ghissassi F, et al. (2012) Carcinogenicity of trichloroethylene, tetrachloroethylene, some other chlorinated solvents, and their metabolites. The Lancet Oncology 13: 1192-1193.
- Nakajima T1, Yamanoshita O, Kamijima M, Kishi R, Ichihara G (2003) Generalized skin reactions in relation to trichloroethylene exposure: a review from the viewpoint of drug-metabolizing enzymes. J Occup Health 45: 8-14. [Crossref]
- Watanabe H (2011) Hypersensitivity syndrome due to trichloroethylene exposure: A severe generalized skin reaction resembling drug-induced hypersensitivity syndrome. The Journal of Dermatology 38: 229-235.
- Committee S General Administration of Quality Supervision/Inspection and Quarantine of the People's Republic of China. The Specification for Marine Monitoring-Part 5: Sediment analysis.
- Boerrigter G, Bril H, Scheper R (1988) Hapten-specific antibodies in allergic contact dermatitis in the guinea pig. International Archives of Allergy and Immunology 85: 385-391.
- Dai Y, Li H, Xie J (2006) The effects of T and B lymphocytes and cytokines on allergic reaction induced by trichloroethylene. China Occup Med 33: 326-332.
- Yue F1, Huang HL, Huang JX, Liang LY, Huang ZL, et al. (2007) HLA-DM polymorphism and risk of trichloroethylene induced medicamentosa-like dermatitis. Biomed Environ Sci 20: 506-511. [Crossref]
- Dai Y, Leng S, Li L, Niu Y, Huang H, et al. (2004) Genetic polymorphisms of cytokine genes and risk for trichloroethylene-induced severe generalized dermatitis: a case-control study. Biomarkers 9: 470-478.
- Ullu E, Tschudi C (1984) Alu sequences are processed 7SL RNA genes. Nature 312: 171-172. [Crossref]
- Lander ES1, Linton LM, Birren B, Nusbaum C, Zody MC, et al. (2001) Initial sequencing and analysis of the human genome. Nature 409: 860-921. [Crossref]
- Witherspoon DJ1, Watkins WS, Zhang Y, Xing J, Tolpinrud WL, et al. (2009) Alu repeats increase local recombination rates. BMC Genomics 10: 530. [Crossref]
- Lo WS1, Lau CF, Xuan Z, Chan CF, Feng GY, et al. (2004) Association of SNPs and haplotypes in GABAA receptor beta2 gene with schizophrenia. Mol Psychiatry 9: 603-608. [Crossref]
- Zhao C, Xu Z, Wang F, Chen J, Ng S-K, et al. (2009) Alternative-splicing in the exon-10 region of GABAA receptor ß2 subunit gene: relationships between novel isoforms and psychotic disorders. PLoS One 4: e6977.
- Lo WS1, Xu Z, Yu Z, Pun FW, Ng SK, et al. (2007) Positive selection within the Schizophrenia-associated GABA(A) receptor beta(2) gene. PLoS One 2: e462. [Crossref]
- Ng SK1, Lo WS, Pun FW, Zhao C, Yu Z, et al. (2010) A recombination hotspot in a schizophrenia-associated region of GABRB2. PLoS One 5: e9547. [Crossref]
- Mei L1, Ding X, Tsang SY, Pun FW, Ng SK, et al. (2011) AluScan: a method for genome-wide scanning of sequence and structure variations in the human genome. BMC Genomics 12: 564. [Crossref]
- Wang J1, Duncan D, Shi Z, Zhang B (2013) WEB-based GEne SeT AnaLysis Toolkit (WebGestalt): update 2013. Nucleic Acids Res 41: W77-83. [Crossref]
- Benjamini Y, Hochberg Y (1995) Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society Series B (Methodological): 289-300.
- Yang JF1, Ding XF1, Chen L2, Mat WK1, Xu MZ3, et al. (2014) Copy number variation analysis based on AluScan sequences. J Clin Bioinforma 4: 15. [Crossref]
- Moore LE, Boffetta P, Karami S, Brennan P, Stewart PS, et al. (2010) Occupational trichloroethylene exposure and renal carcinoma risk: evidence of genetic susceptibility by reductive metabolism gene variants. Cancer Research 70: 6527-6536.
- Shimazu T1, Hirschey MD, Hua L, Dittenhafer-Reed KE, Schwer B, et al. (2010) SIRT3 deacetylates mitochondrial 3-hydroxy-3-methylglutaryl CoA synthase 2 and regulates ketone body production. Cell Metab 12: 654-661. [Crossref]
- Li H, Dai Y, Huang H, Sun Y (2006) [Polymorphisms of aldehyde and alcohol dehydrogenase genes associated with susceptibility to trichloroethylene-induced medicamentosa-like dermatitis]. Journal of Hygiene Research 35: 149-151.
- Xinyun XU JM, Kanlang MAO (2012) Altered expression of hepatic metabolic enzyme genes, immune-related genes, oncogene and apoptotic genes in patients with trichloroethylene-induced allergic disorder. The 6th International Congress of Asian Society of Toxicology.
- Sano Y, Nakashima H, Yoshioka N, Etho N, Nomiyama T, et al. (2009) Trichloroethylene liver toxicity in mouse and rat: microarray analysis reveals species differences in gene expression. Archives of Toxicology 83: 835-849.
- Dai Y, Leng S, Li L, Niu Y, Huang H, et al. (2009) Effects of genetic polymorphisms of N-Acetyltransferase on trichloroethylene-induced hypersensitivity dermatitis among exposed workers. Industrial Health 47: 479-486.
- Lipscomb JC, Garrett CM, Snawder JE (1997) Cytochrome P450-dependent metabolism of trichloroethylene: interindividual differences in humans. Toxicology and Applied Pharmacology 142: 311-318.